[Scikit-learn]시계열 데이터의 클러스터링(Feat. Dynamic Time Warping)
Clustering?
비지도 학습의 일종으로 정답이 있어야 학습을 시키는 지도학습(예측,분류)방법과는 다르게 정답이 없이도 데이터의 특성을 거리로 환산하여 비슷한 데이터들끼리 엮어주는 기법이다. 클러스터링 기법으로는 K-means 클러스터링이 가장 유명하다.
보통 데이터의 클러스터링은 유클리디안 거리를 이용하여 진행하는데 시계열 데이터의 클러스터링은 조금 다르다.
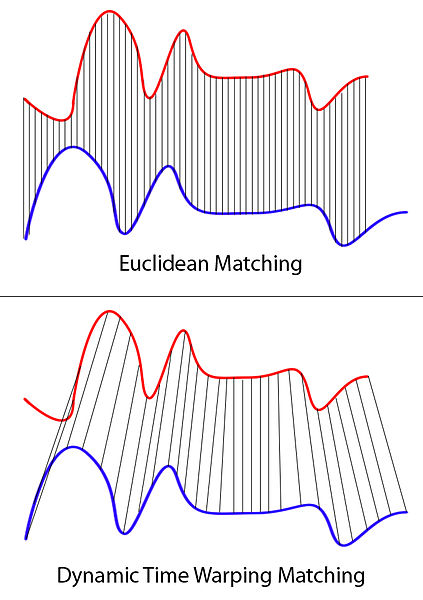
아래 그림과 같이 비슷한 모양이더라도 유클리디안 방식으로 매칭시킨다면 완전 다른 형태의 그래프로 인식할 것이다.
하지만 Dynamic Time Warping (이하 DTW) 방식을 사용한다면 그래프의 전체적인 흐름을 보고 매칭시키는 꼴이되어 그래프 간의 유사성이 높게 나올 것이다.
< 참고 >
towardsdatascience.com/how-to-apply-k-means-clustering-to-time-series-data-28d04a8f7da3
Dynamic Time Warping 에 관해 쉽게 설명해주고있다.
How to Apply K-means Clustering to Time Series Data
Theory and code for adapting the algorithm to time series
towardsdatascience.com
en.wikipedia.org/wiki/Dynamic_time_warping
Dynamic Time Warping 함수 구현 내용이 자세히 나와있다.
Dynamic time warping - Wikipedia
Two repetitions of a walking sequence recorded using a motion-capture system. While there are differences in walking speed between repetitions, the spatial paths of limbs remain highly similar.[1] In time series analysis, dynamic time warping (DTW) is one
en.wikipedia.org